Recently I’ve been learning about Spark, which motivated me to really understand MapReduce, the underlying framework that greatly simplifies batch processing at scale.
Luckily, once I read the paper and broadly grasped how all the pieces are glued together, it wasn’t too hard hacking together a simple, lightweight system running on my laptop. I chose Rust as it’s been on my radar for a while due to its memory safety, and I was looking for an excuse to try out its async model. You can find the full code here.
I wanted to explore things I learned throughout, challenges of building even simple distributed systems, and ideas I think are worth further pursuing.
Overview
MapReduce is nothing more than an abstraction for parallel computation. You define two functions, map() and reduce(), and the framework will call those functions on your potentially large dataset, handling computation across a cluster of machines without you having to worry about synchronization.
The user-defined map() function transforms your data into key/value pairs, while the reduce() function takes a large number of these key/value pairs and “reduces” them to a smaller set.
For instance, imagine a dataset that consists of customers and their spending in a day. A map() function could take all the (customer name, amount) pairs and capitalize the names of the customers. A reduce() function could then collect all the pairs with the same name and reduce them to just one pair, summing up all the individual amounts.
// Figure 1: A simple MapReduce job
maria | $12.02 maria | $41.4
george | $14.19 cecilia | $1441.1
maria | $1.00 marcus | $100.01
| |
map map
| |
"Maria" | $12.02 "Maria" | $41.4
"George" | $14.19 "Cecilia" | $1441.1
"Maria" | $1.00 "Marcus" | $100.01
| |
----------- collect -----------
|
"Cecilia" | $1441.10
"George" | $14.19
"Marcus" | $100.01
"Maria" | $1.00
"Maria" | $41.4
"Maria" | $12.02
|
reduce
|
"Cecilia" | $1441.10
"Marcus" | $100.01
"George" | $14.19
"Maria" | $54.42
Note that prior to the reduce phase, the output from the map phase is sorted by an intermediary, called here the “collect” phase. This is essentially a preprocessing phase to so the reduce can run fast. In Rust, these two functions could look something like:
use std::collections::HashMap;
fn map(pair: (&str, i32)) -> (String, i32) {
let mut word = pair.0.chars();
match word.next() {
None => (String::new(), pair.1),
Some(c) => (c.to_uppercase().chain(word).collect(), pair.1),
}
}
fn reduce(pairs: Vec<(&str, u32)>) -> HashMap<&str, u32> {
let mut reduced_pairs = HashMap::new();
for pair in pairs.iter() {
match reduced_pairs.get(pair.0) {
None => reduced_pairs.insert(pair.0, pair.1),
Some(val) => reduced_pairs.insert(pair.0, val + pair.1),
};
}
reduced_pairs
}
Design
A basic design consists of one master node, and one or more worker nodes. The master initializes a number of map and reduce tasks, typically specified by the user, and keeps metadata about those tasks, such as its completion status and whether it is a map or reduce task.
Once a worker boots, it will send a RPC to the master, asking for a task. The master will look through its list of available tasks and assign one to the worker. Note that the master can only assign map tasks at first, and cannot begin assigning reduce tasks until every map task is complete. When a worker completes a map task, it will notify the master, then becomes idle again, during which a master can assign it another task.
Once all map tasks are complete and the reduce phase begins, workers are given multiple files stored on disk, which are also the output files of the previous map phase. So a reduce worker must be given the location of these files, read them, call its reduce function, then write the final output onto disk.
The master must also keep track of how much time a worker is spending on a given task; if some limit is crossed, perhaps due to the worker clogging up or dying, that task is revoked from the worker and handed out to another worker.
Below is a visual diagram of the entire process, stolen from the original paper. 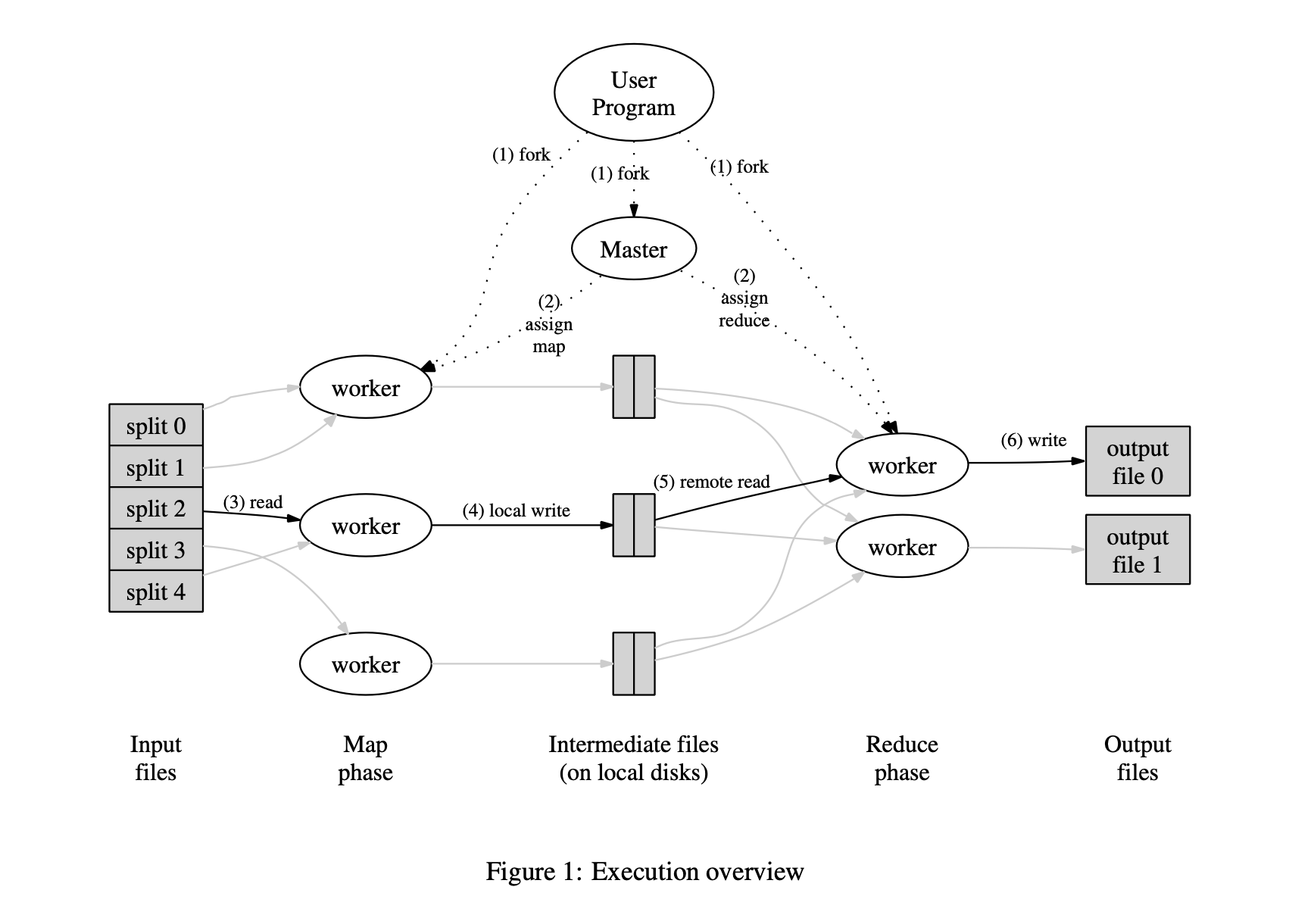
Implementation
Both the master and worker processes essentially sit in an infinite while loop, in which the former waits for a request and the latter sends one whenever it becomes idle.
For communication, we use the tonic gRPC framework to generate request/response types from protobuf structs, which also handles serialization for us. Furthermore, as Rust does not have a built-in async runtime, we defer to the popular crate tokio. Putting it all together, we can easily write server/client code that represents a master/worker interaction.
Below is what a simple master implementation looks like.
async fn send_task(
&self, request: Request<TaskRequest>,
) -> Result<Response<TaskResponse>, Status> {
let client_options = ClientOptions::parse(MONGO_HOST)
.await.unwrap_or_else(|err| {
eprintln!("ERROR: could not parse address: {err}");
exit(1)
}); // initialize client handler
let client = Client::with_options(client_options).unwrap_or_else(|err| {
eprintln!("ERROR: could not initialize client: {err}");
exit(1)
});
let db = client.database(DB_NAME);
// Get existing map tasks from database
let coll = db.collection::<mongodb::bson::Document>(MAP_TASKS_COLL);
let distinct = coll.distinct("name", None, None).await;
// Loop over all tasks looking for an idle one to assign
for key in distinct.unwrap() {
let res = mongo_utils::get_task(
&client, DB_NAME, MAP_TASKS_COLL, key.as_str().unwrap())
.await;
// If a single map task is not done,
// set a flag to indicate map phase unfinished
if !(res.4.unwrap()) {
map_phase_done = false;
}
// If not assigned, hand out this task
if !(res.1.unwrap()) {
let response_filename = &res.0.unwrap();
let tasknum = res.3.unwrap();
let reply = TaskResponse {
task_name: response_filename.to_string(),
is_assigned: false, is_map: true,
tasknum, done: false,
};
update_assigned(
&client, DB_NAME, MAP_TASKS_COLL,
response_filename, true).await;
return Ok(Response::new(reply));
}
}
}
And the worker:
pub async fn boot(&self) -> Result<(), Box<dyn std::error::Error>> {
// Initialize client
let client_options = ClientOptions::parse("mongodb://localhost:27017")
.await.unwrap_or_else(|err| {
eprintln!("ERROR: could not parse address: {err}");
exit(1)
});
let db_client = Client::with_options(client_options).unwrap_or_else(|err| {
eprintln!("ERROR: could not initialize database client: {err}");
exit(1)
});
let db_name = "mapreduce";
let coll_name = "state";
let record_name = "current_master_state";
let n_map = mongo_utils::get_val(&db_client, db_name, coll_name, record_name, "n_map")
.await.unwrap();
let n_reduce =
mongo_utils::get_val(&db_client, db_name, coll_name, record_name, "n_reduce")
.await.unwrap();
let mut client = TaskClient::connect("http://[::1]:50051").await?;
// create new request asking for a task
let request = tonic::Request::new(TaskRequest { id: process::id() });
let response = client.send_task(request).await?;
// get info about the task
let is_map = response.get_ref().is_map;
let task_name = &response.get_ref().task_name;
let reduce_tasknum = calculate_hash(task_name) % n_reduce as u64;
if is_map {
// process map task and write results to disk
...
} else {
// process reduce task and write results to disk
...
}
}
#[tokio::main]
async fn main() {
// Initialize worker
let worker: Worker = Worker::new(process::id(), false);
worker
.boot()
.await
.expect("ERROR: Could not boot worker process.");
}
We also need to keep track of some shared state between the master and the workers, such as whether the entire job is finished or not. Keeping track of this information in memory as fields in the master seemed difficult in the face of concurrent updates as well as Rust’s lifetime and borrowing rules. Plus, what if the master dies and we have to start all over again because we lose track of such basic information, despite having existing work persisted to disk?
So here we defer to use some external storage, in our case a persistent Mongo instance. Though this only works since we are on one machine; if that were not the case, we would likely need something like Zookeeper, which is built for maintaining this sort of metadata while offering synchronization across many nodes.
Areas of work
Some areas for potential improvements, in no particular order.
- Eliminating disk I/Os!
- Better concurrency model for shared state - something like Zookeeper. Or perhaps, sharing state is the wrong answer, and we should be using message passing instead, something that Golang offers natively.
- Persistence from master crash - maybe involving a worker taking over as the master through some election process.
- Better persistence from worker crash: instead of having another worker start over a failed task, we could have some sort of checkpointing so that previous progress from a failed worker is not wasted.
References
- MIT’s distributed systems course, where I got inspiration for the design
- Original MapReduce paper
- Spark paper
- Zookeeper docs on consistency guarantees
- Article on the background of async Rust